Implement GitOps on Kubernetes with ArgoCD and Kustomize
GitOps is a term first coined and popularized at Weaveworks. GitOps can in it’s most concise form be described as a philospohy or a workflow on how infrastructure and application code changes/deployments should be applied to a desired state where Git is the single source of truth. GitOps is not limited to Kubernetes but in the Kubernetes ecosystem we have specialized tools that can easily helps us implement GitOps due to the already declarative nature of Kubernetes manifests.
In this guide we will build a complete GitOps workflow on Kubernetes using ArgoCD as the GitOps engine and orchestrated from Github Actions as the CI part.
What is GitOps and why it matters
The pillars of GitOps are:
- Git is the single source of truth for the desired state of the whole system. By viewing Git one should be able to describe the whole Kubernetes setup
- All changes to the desired state are Git commits. Drift, i.e. changes outside of git, will automatically trigger a convergenece to the desired state described in Git
- Built in observability - we should be able to detect that the desired and observed states are the same or diverged
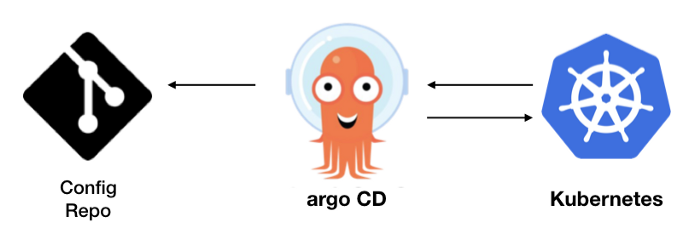
In Kubernetes two popular GitOps tools are ArgoCD and Flux. Both are installed in Kubernetes and they are configured to watch one or several Git repos storing declarative Kubernetes manifests. Whenever someone pushes changes to that repo the tool will take action to update the cluster accordingly. In other words we are using Kubernetes to update the Kubernetes cluster itself! (think push vs pull)

To be honest when I first read about GitOps I scoffed at it, to my ears it sounded like someone was trying to reinvent CI/CD with a new buzzword. However after working on large Kubernetes environments I can definitely say that GitOps is THE best way to manage Kubernetes objects and application deployments. Here are some arguments why:
- Simplicity - GitOps removes the need for brittle and imperative CD scripts
- Security - by following the principle of least permission we grant the GitOps tool permission to provision objects. The CI system does not need credentials or know to how to apply changes to the Kubernetes environment, all changes are done by PRs in Git
- Discoverability - just by looking at Git one can describe the whole Kubernetes setup and we can use Git as an audit-log on who did what and when
- Standardization - the GitOps workflow describes a standard thus onboarding for both devs and ops is greatly simplified
To sum it up: one of the more difficult things i experience when working with clients are what part of the terraform/cloudformationkubernetes/ansible are actually applied and to which AWS account / k8 cluster. With GitOps that confusion mostly goes away.
Prereqs
With the theory out of the way lets review what prereqs we need to get starting on our GitOps workflow:
- A GitHub account
- A DockerHub account
- kubectl
- A Docker installation (Docker Desktop on Windows and MacOS or appropriate packages on your Linux distribution)
- A running Kubernetes cluster (any flavor works but here I will use Kind)
You can use this Git repo to follow along this guide, easiest way is to just fork it.
GitOps Workflow
With a Go application as a starting point we will use GitHub Actions for the CI part (compiling the application and build a docker image). We will use Kustomize as the tool for managing the Kubernetes manifests and lastly ArgoCD as the GitOps tool to orchestrate our application deployments. The pipeline will look like this:
Compile, build image and push to DockerHub -> Inject new image tag into Kubernets manifest using Kustomize -> Push changes to git repo -> ArgoCD will take over to deploy our applicationKubernetes (Kind) and ArgoCD setup
After installing Kind and kubectl we can boot up our cluster. Use the following configuration when initializing the Kind cluster (or just use the kind-config.yaml provided in the repo):
Now we can set up Kind, Ingress and ArgoCD with these commands:
$ kind create cluster --config kind-config.yaml
# install the Nginx ingress
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/static/provider/kind/deploy.yaml
# install ArgoCD
$ kubectl create namespace argocd
$ kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
# use port-forwarding to access the ArgoCD UI
$ kubectl port-forward --address 0.0.0.0 svc/argocd-server -n argocd 8080:443
# get the admin password
$ kubectl get pods -n argocd -l app.kubernetes.io/name=argocd-server -o name | cut -d'/' -f 2Head over to localhost:8080 and login with admin and password from the last command. We’ll come back to Argo UI in a bit but first lets talk about the Go application and it’s k8 manifests which will be handled by Kustomize
Go Application and k8 manifests
Our Go application is fairly simplistic, I’ve left out the imports and the main function. As we can see below we have two http endpoints, the root endpoint (helloArgo) will output a json response with the commit id the application was built on. For that we’re using the Version variable, in the compilation step we’ll inject the git hash so “dev” is just a placeholder.
The Dockerfile is fairly basic (see below). It’s a multistage build, where we’ll compile the source code in one container and transfer it to a tiny scratch image.
Kustomize blabla
kustomize/
├── base
│ ├── deployment.yaml
│ ├── ingress.yaml
│ ├── kustomization.yaml
│ └── service.yaml
└── envs
├── dev
│ ├── deployment-patch.yaml
│ └── kustomization.yaml
└── test
├── deployment-patch.yaml
└── kustomization.yamlSync ArgoCD with our Git repo
Github Actions pipeline